



Higson engine is known for its very high efficiency and low latency. Despite this, the development team strives to push the boundaries and continually improve its performance.
Higson engine 4.1 brings a lot of performance improvements: faster decision table lookups, faster type conversions (numbers, dates, integers), faster matchers. There are also significant improvements in function calls, decision table load latencies and memory consumption.
Memory Consumption
One area that has been optimized recently is memory usage. Many Higson-powered systems have very extensive configurations. There are many deployments where the Higson configuration has over 1000 decision tables. In fact, we know of several applications with more than 3000 decision tables.
Decision table lookup in our business rules engine is very fast (typically 1-5 microseconds) because decision table is kept in memory as a carefully designed tree-like structure called level index.
When there are a lot decision tables, memory consumption becomes a very important factor and has a significant impact on application performance.
As a result of the work of the performance team, memory usage has been significantly reduced:
- by over 40% for the most typical decision tables,
- by 10%-20% for the less common decision tables.
Importantly, these improvements were achieved without compromising search performance — in fact, search latency has improved as well.
The following section provides a detailed explanation of the changes that made this possible.
How Higson's Decision Table Works Under the Hood
To understand how to reduce memory consumption, we first need to understand what the decision table index looks like.
For the purposes of the following analysis, let us take a decision table of the following shape:
- 3 input columns (conditions)
- 2 output columns (result)
The simplest way an application can retrieve a value from this decision table is as follows:
ctx = new HigsonContext("product", "P2", "risk", "B", "fund", "F2")
ParamValue out = engine.get(decisionTable, ctx)
var fee = out.getBigDecimal("fee") // 3
var limit = out.getInteger("limit") // 1400
When accessing a decision table for the first time, Higson reads the metadata and the entire matrix from the database and then builds an index that will be held in memory from then on.
The image below shows the index for our sample decision table.
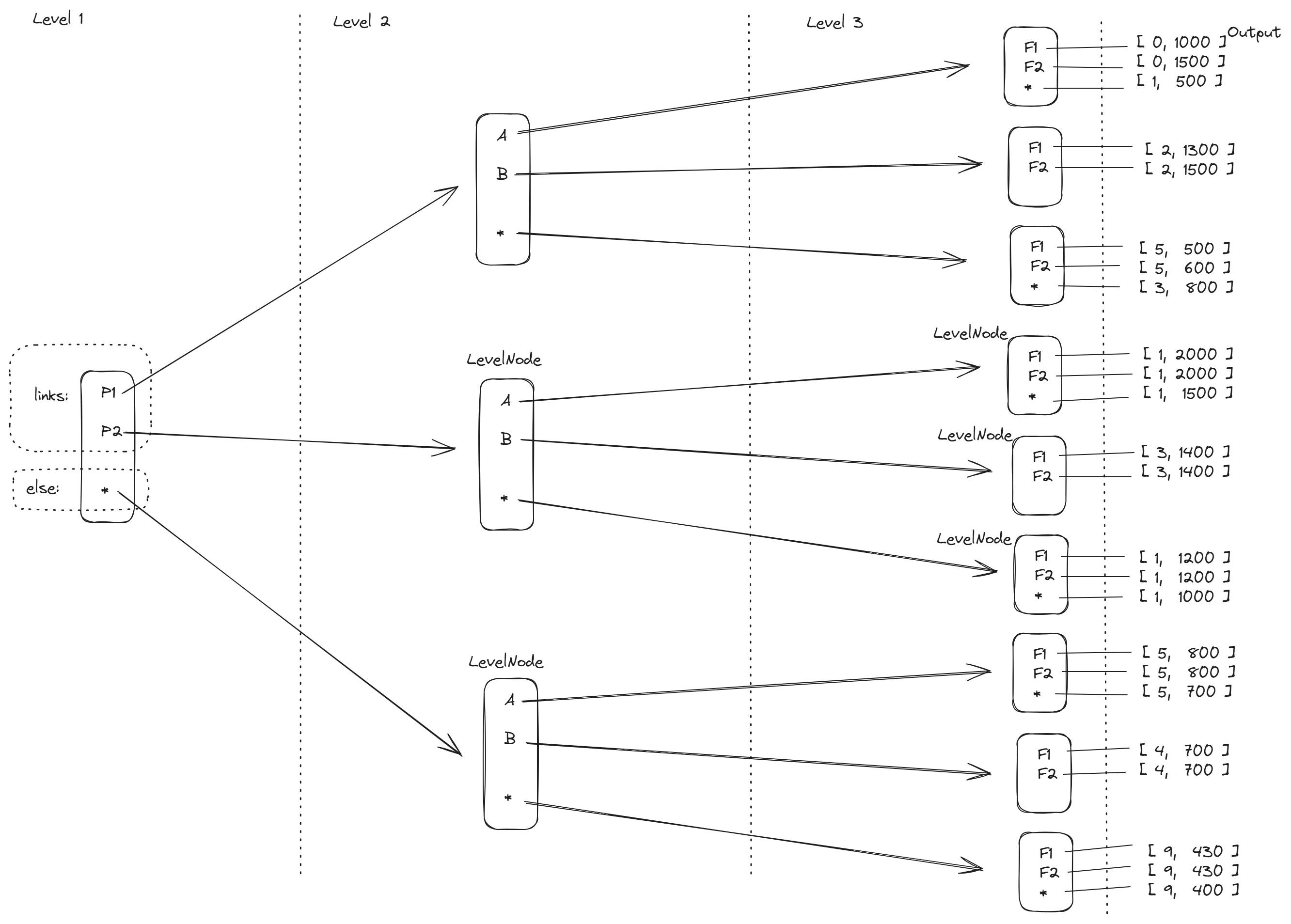
Let’s take a look at the diagram above. The index has a height of 3, because there is a separate level for each input column in the decision table. On the first level (product), the possible values defined in the matrix are: P1, P2, and "*" as the else symbol. Using the default matching strategy, the Higson engine finds the path from the first to the last level representing the input data. At each node (LevelNode), it performs a lookup in a hash table called links, attempting to find a link to the node in the next level.
In other words:
- At the first level, the index contains one node with all possible values defined in the first input column of the matrix,
- At the second level, the index contains multiple nodes that can be reached after determining the value from the first level,
- At any level k the index contains nodes that can be reached from k-1 level by any valid combination of input data.
This structure has an interesting property:
If T(n,k) is the number of hash table lookups for matrix with n rows and k conditions, then:
For the average case:
T(n,k) = 1 + T(n, k-1) = k
For the worst case:
T(n,k) = 1 + 2*T(n, k-1) = 2^k – 1
The number of hash table lookups does not depend on the number of rows n.
So, if we are not using matchers, we can say:
T(n) = O(1)
Index Memory Footprint
For large decision tables, we can expect thousands or even millions of nodes. Each node takes some memory from the heap. We know of many systems that use dozens of large decision tables and hundreds of medium-sized ones. So the node’s memory footprint has a significant impact on the total memory usage.
Let's see what the LevelNode class contains:
public class LevelNode<T> {
String value;
Map<String, LevelNode<T>> links;
LevelNode<T> elseNode;
List<T> leafList;
LevelNode<T> parent;
LevelIndex<T> index;
}
The meaning of the individual fields is as follows:
- value is the content of the matrix cell
- links is a hash map of all possible values that can continue from this node
- elseNode is a node for the “*” symbol, representing “else” condition is best-match searching mode
- leafList exists only for the leaf nodes and contains all output rows for given matching path (yes, it is possible that the response contains multiple rows)
- parent is a reference to the parent node
- index is a reference to the root which holds table’s metadata
Now let's see what is the memory footprint of the LevelNode object. We will use the JOL CLI tool to inspect the object structure. JOL or Java Object Layout (github.com/openjdk/jol) is a very precise tool that uses the JVMTI to examine the details of classes or objects.
We run the cli command for Higson engine ver. 4.0:
$ java -jar jol-cli-0.17.jar internals -cp higson-runtime-4.0.18.jar LevelNode
# VM mode: 64 bits
# Compressed references (oops): 3-bit shift
# Object alignment: 8 bytes
# ...
io.higson.runtime.engine.core.index.LevelNode object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0x00c14800
12 4 LevelNode.value null
16 4 LevelNode.links null
20 4 LevelNode.elseNode null
24 4 LevelNode.leafList null
28 4 LevelNode.parent null
32 4 LevelNode.index null
36 4 (object alignment gap)
Instance size: 40 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
We can see that:
- object header takes 12 bytes
- 4 bytes for a reference to a value String (placed in the string intern pool)
- 4 bytes for a reference to a links map
- 4 bytes for a reference to an elseNode object
- 4 bytes for a reference to a leafList collection
- 4 bytes for a reference to a parent node
- 4 bytes for a reference to the index root
- 4 bytes of object alignment gap (object size must be a multiple of 8 bytes)
The total space occupied by each instance is 40 bytes.
All of these fields are used by the index logic. So, can we remove any of them without sacrificing lookup latency performance?
The parent field is used only by one method to construct a level path in a recursive way. And after some thought we came to the conclusion that this method could be refactored so that it doesn't use the parent field at all.
This means we can remove this field from the LevelNode class.
Let's see how memory footprint of LevelNode class has changed:
$ java -jar jol-cli-0.17.jar internals -cp higson-runtime-4.1.0.jar LevelNode
# VM mode: 64 bits
# Compressed references (oops): 3-bit shift
# Object alignment: 8 bytes
# ...
io.higson.runtime.engine.core.index.LevelNode object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0x00c14800
12 4 LevelNode.value null
16 4 LevelNode.links null
20 4 LevelNode.elseNode null
24 4 LevelNode.leafList null
28 4 LevelNode.index null
Instance size: 32 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
Now, the total space taken up by each instance is only 32 bytes. No more parent reference and no need for alignment gap.
Why does the reference takes 4 bytes only?
4 bytes (32 bits) can hold only 2^32 different values.
Using 32-bit pointers we can only address 2^32 bytes, which corresponds to only 4 GB.
JVM uses very clever trick here. Since all objects must be 8 bytes aligned, the address is always a multiple of 8. In other words, the last 3 bits of the pointer are always 0.
So the JVM can add the 3 most significant bits to the left. The pointer can then address 2^35 = 32 GB. When storing a reference on the heap, the JVM shifts these 35 bits to the right dropping the last 3 zeros so that it can be stored in 4 bytes.
So, if you use a heap no larger than 32 GB and a GC other than ZGC, then the HotSpot JVM will enable compressedOops mode and each reference will cost only 4 bytes.
You can check if your JVM runs with CompressedOops enabled by typing:
jcmd <PID> VM.flags -all | grep UseCompressedOops
Matrix Output Cells
Now let's look at the leaf node. It contains a collection of PreparedOutput objects. Each PreparedOutput contains an String[] array of consecutive output cells.
What is the overhead associated with such a wrapper:
# VM mode: 64 bits
# Compressed references (oops): 3-bit shift
# ...
io.higson.runtime.engine.core.prepared.PreparedOutput object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) N/A
8 4 (object header: class) N/A
12 4 String[] PreparedOutput.cells N/A
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
In simple terms, this wrapper object has 12 bytes for the header and 4 bytes for the reference to the output array.
Do we need such a wrapper?
Of course not, we can keep a reference to the output array directly in the leaf node.
So a small modification in the index implementation saves 12 bytes per matrix row.
Results
After the changes described (and a few other minor modifications) we managed to significantly reduce the memory consumption of decision tables.
The graph below shows the differences between version 4.0 and 4.1.
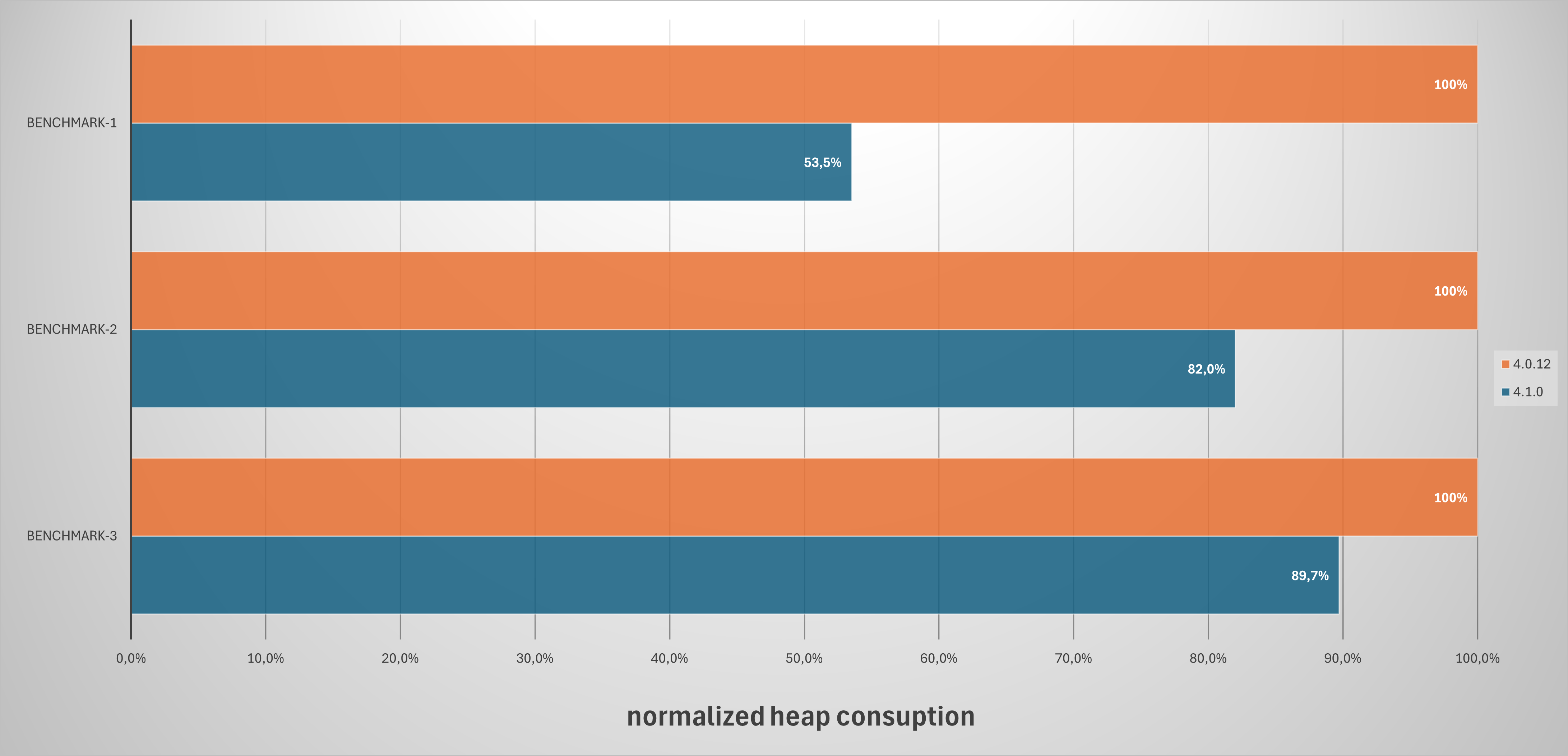
Benchmark-1 uses 2 decision tables with 3 conditions and 1 output. First table has 1 million rows, second table has 100k rows. The tables are constructed in the most common way and are therefore very representative. Higson engine 4.1 needs only 53% of what is needed by 4.0.
Benchmark-2 and Benchmark-3 uses much less common decision tables with 27 columns and 200k rows, while still offering the 10-20% reduction in memory usage.
Wrapping Up
Memory consumption reduction is one of many optimizations available in Higson 4.1. The main improvements are listed below.
Higson Engine 4.1 brings:
- over 40% heap usage reduction for most common decision tables,
- about 50% reduction of function's call overhead latency in multi-threaded environment
- faster data type handling for output columns, huge boost for numbers and dates
- significant boost when using between, in and not-in matchers
- speedup in decision table loading, especially for large ones
In general, analyzing the nuances of the engine internals and trying to increase its efficiency involves a lot of work.
So is the effort worth it?
Building a product or a library (like Higson engine) is a specific task. Each improvement is immediately available to all applications using Higson business rules engine.
All of these systems could benefit from improvements just by upgrading the engine version.
And yes, we are convinced that the effort is worth it.
